带你摸透生信常用的18种回归分析模型
发布时间:2025-01-10
浏览次数:6894
作者:东极药物
回归模型是研究自变量X与因变量Y的影响关系最常用的方法,但不同的回归模型,有不同的适用条件。今天我们整理了生信领域常用的18种回归分析模型!除了总结归纳每个模型的用途和特点,还附有具体案例,更有助于理解哦···
回归模型是研究自变量X与因变量Y的影响关系最常用的方法,但不同的回归模型,有不同的适用条件。
今天我们整理了生信领域常用的18种回归分析模型!除了总结归纳每个模型的用途和特点,还附有具体案例,更有助于理解哦~
一、线性回归(Linear Regression)
①定义:即通过线性组合来说明自变量和因变量之间的关系。这种关系的强弱程度,利用自变量的线性组合可以预测因变量的能力大小。
②适用场景:当自变量和因变量之间存在线性关系时,或需要对结果的影响有明确解释时。
③举例:在临床试验中,可以使用线性回归来研究血压与年龄、降压药剂量之间的关系。
④R语言代码:model <- Im(bp ~ age + dosing,data = my_data)
二、多重线性回归(Multiple Linear Regression)
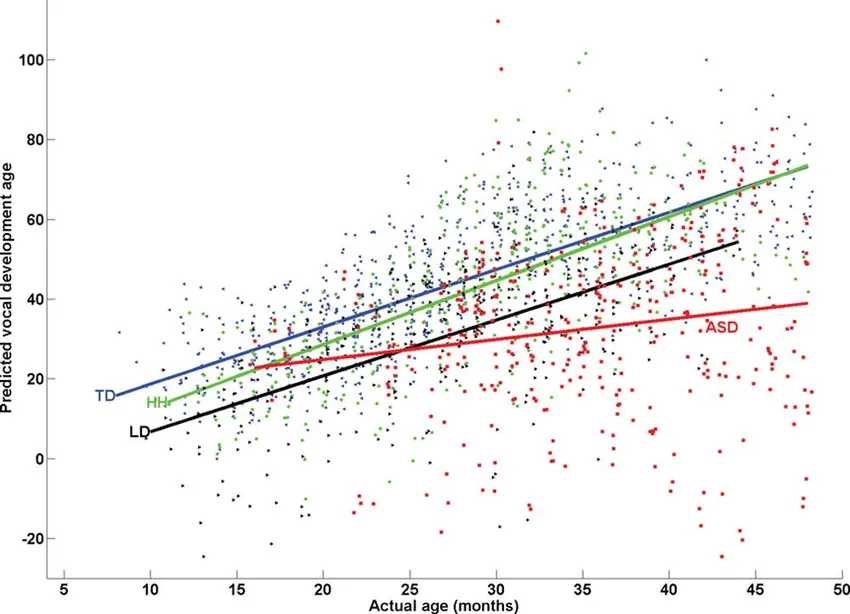
①定义:又称为多因素线性回归,研究一个因变量与多个自变量之间的数量依存关系。
②适用场景:当因变量是连续的数值时,或多个自变量之间存在高度相关时。
③举例:可以运用多重线性回归来研究吸烟、CA(癌症)、固位方式、性别、年龄等多个因素中,究竟哪些因素对骨吸收产生显著影响。
④R语言代码:model_formula <- as.formula(paste(dependent_variable,"~"
paste(independent_variables,collapse = "+"))
三、套索回归(Lasso Regression)
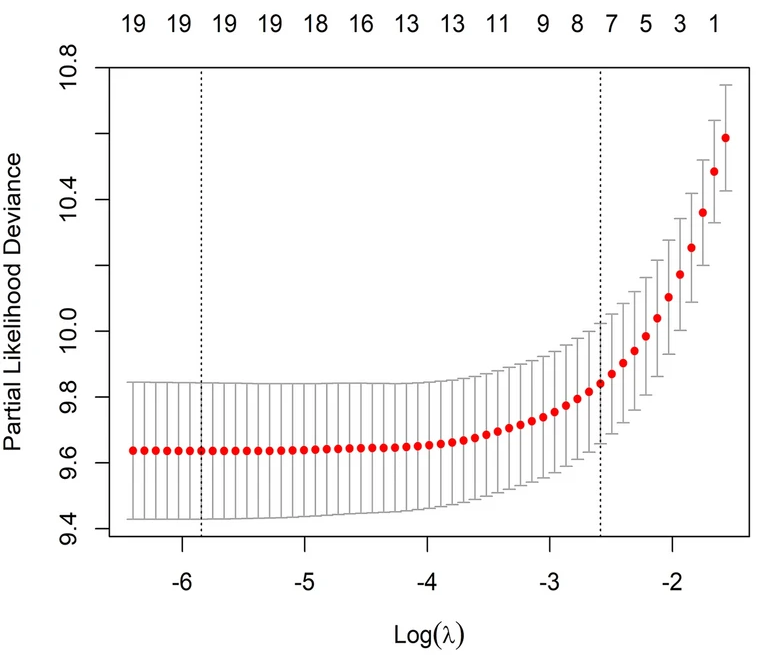
①定义:通过引入L1正则化项(即变量系数的绝对值之和)来实现变量选择和参数压缩,达到防止模型的过度拟合,并控制模型的复杂度,提高模型的泛化能力。
②适用场景:通常适用于需要进行特征选择的场景,或者特征数量多于样本数量的情况下。
③举例:研究从心衰患者的性别、年龄等自变量中筛选特征变量,探究其与心力衰竭严重程度之间的关系。
④R语言代码:需要使用特定包实现(如glmnet包)lasso_model <- glmnet(x = as.matrix(heart_failure_data[c(1,2)]),y = heart_failure_dataSgender,alpha = 1)
四、Cox回归(cox Regression)
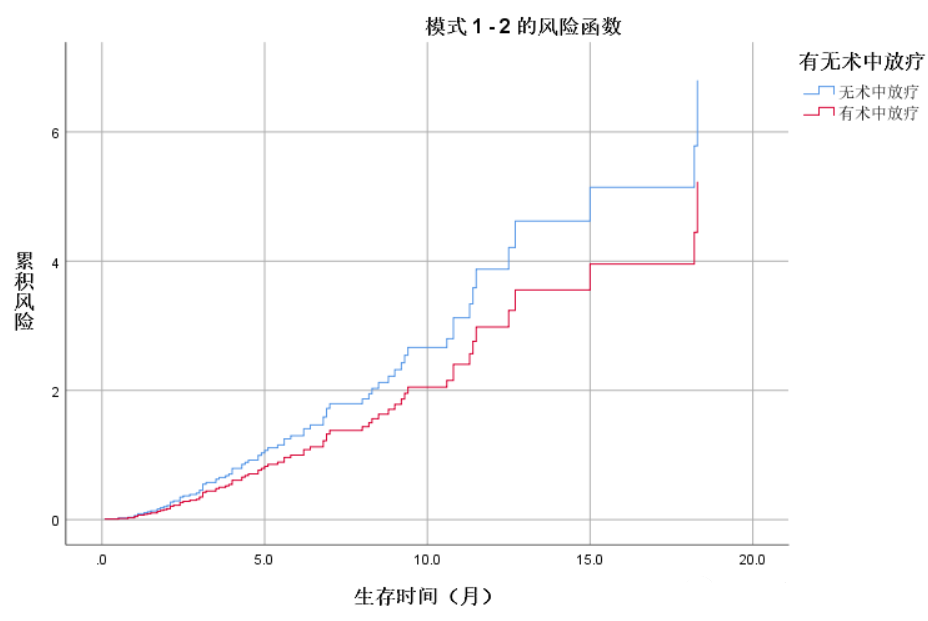
①定义:一种半参数回归模型,主要用于分析生存时间数据。以生存结局(如事件发生或未发生)和生存时间作为因变量,可以同时考虑多个因素对生存时间的影响。
②适用场景:当处理连续性数据时。
③举例:研究患者的生存时间以及与生存时间相关的预测因素。
④R语言代码:cox_model <- coxph(Surv(time,censor) ~ factorl + factor2 + factor3, data = df)
五、岭回归(Ridge Regression)
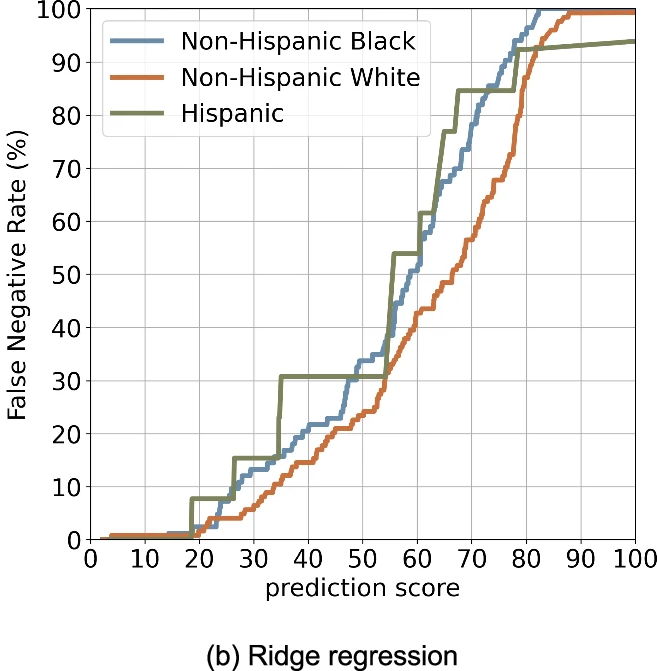
①定义:一种线性回归的改进方法,通过引入L2正则化项来避免过拟合,处理共线性问题。
②适用场景:当数据存在多重共线性,且不希望模型系数缩减到零时。
③举例:基因表达数据的分析,筛选重要基因。
④R语言代码:需要使用特定包实现(如glmnet包)
六、逐步回归(stepwise Regression)
①定义:一种通过系统地添加或删除自变量来建立最优的多元线性回归模型。
②适用场景:当处理高维数据时,或需要建立时间序列预测模型,预测未来的趋势和变化时。
③举例:用来识别与癌症患者预后(如生存率)相关的生物学标志物。
④R语言代码:cox_model <- coxph(Surv(time,status) ~ .,data=data)
七、逻辑回归(Logistics Regression)
①定义:用于预测二元结果的回归方法,根据给定的自变量数据集来估计事件的发生概率,因变量的范围在0和1之间。
②适用场景:用于处理二分类问题,如疾病的发生概率、患者的生存率等。
③举例:预测患者是否患有某种疾病。
④R语言代码:model <- glmnet(y ~ x1 + x2 + x3,family = binomial, data)
八、弹性网络回归(Elastic NetRegression)
①定义:结合了岭回归和套索回归的优点,通过同时使用L1和L2正则化项,处理高维数据和多重共线性问题。
②适用场景:当数据既存在多重共线性又希望进行特征选择时。
③举例:根据患者的年龄、性别、肿瘤类型、基因表达水平以及临床特征等数据,研究肿瘤标志物与患者预后之间的关系。
④R语言代码:model <- glmnet(x = as.matrix(traindata[,-last(traindata)]),y = traindatalast(traindata),family="gaussian",alpha = 1)
九、多项式回归(Polynomial Regression)

①定义:使用多项式函数来拟合数据,处理非线性关系的回归问题。
②适用场景:当自变量和因变量之间的关系是非线性的,且这种关系可以通过多项式来近似时。
③举例:研究药物剂量与治疗效果之间的关系,以最大化疗效、减少副作用并确认最佳剂量。
④R语言代码:poly_model <- lm(effect ~ poly(dose, 2, raw=TRUE), data=data)
十、分位数回归(Quantile Regression)
①定义:通过估计响应变量的条件分位数来建模的回归方法,能够捕捉数据的异质性。
②适用场量:用于预测条件均值,以及预测条件中位数或其他任何分位数。
③举例:研究不同抑郁程度下,睡眠时间和抑郁水平关联是否存在异质性。
④R语言代码:quantreg_model <- rq(dep ~ hours + as.factor(group),ts = dep, data = data)
十一、决策树回归(Decision TreeRegression)

①定义:一种基于树结构的预测模型,通过递归地将数据集分割成子集,直到满足某些停止条件(如最小数据点数或最大深度)。
②适用场景:当数据具有复杂的非线性关系或需要自动进行特征选择时。
③举例:建立一个决策树模型,用来研究银屑病患者治疗效果的影响因素。
④R语言代码:tree_model <- rpart(!!sym(response_var) ~ ., data = psoriasis, method "class”)
十二、随机森林回归(Random Forest Regression)
①定义:一种通过构建多个决策树并结合它们的预测结果来提高预测精度和稳定性的回归模型。
②适用场景:处理高维数据、处理缺失值、防止过拟合。
③举例:基于多个基因的表达数据预测药物反应。
④R语言代码:需要使用特定包实现(如randomForest包)
十三、梯度提升回归(Gradient Boosting Regression)
①定义:通过逐步构建多个弱学习器(如决策树),并根据前一轮的预测误差调整后续学习器的权重来改进模型。
②适用场景:处理非线性数据、处理异常值、处理缺失值。
③举例:基于基因表达数据预测癌症预后。
④R语言代码:需要使用特定包实现(gbm或xgboost包)
十四、支持向量回归(Support VectorRegression)
①定义:通过在特征空间中构建一个超平面来最小化预测误差,同时最大化超平面与数据点之间的间隔。
②适用场景:当数据具有高维特征,且需要模型对异常值不敏感时。
③举例:通过与DNA序列特征、蛋白质序列特征等结合,实现高效的基因分类。
④R语言代码:svm_model <- svm(features,labels, type='C-classification')
十五、XGBoost回归(eXtreme Gradient Boosting)
①定义:一种高效的梯度提升决策树算法,通过引入正则化项和收缩策略来防止过拟合,并支持分布式计算。
②适用场景:当处理复杂的、非线性的数据情况时。
③举例:通过分析患者的基因信息以及其他关键特征,来预测某种药物对患者的治疗效果。
④R语言代码:xgb_model <- xgb.train(params, data = train_dataset, nrounds = 100)
十六、LightGBM回归(Light Gradient Boosting Machine)
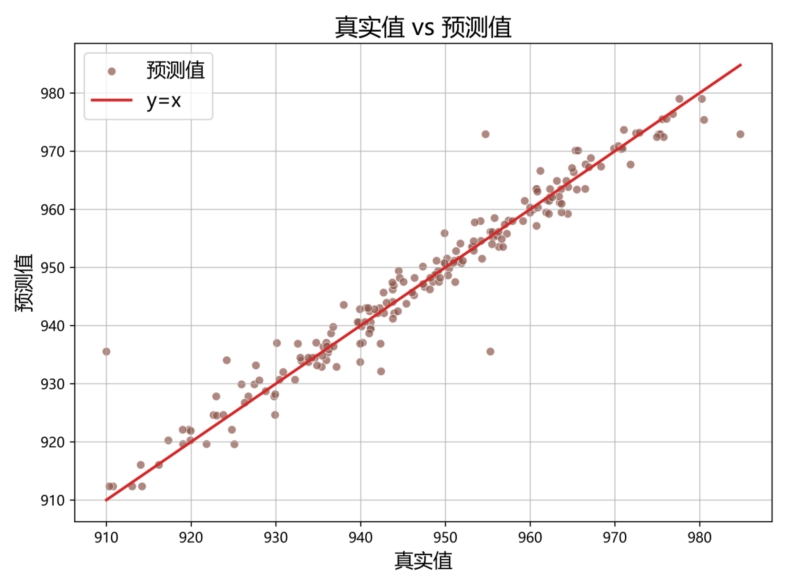
①定义:一种基于梯度提升的决策树算法,通过优化直方图算法和基于梯度的单边采样技术来提高训练速度和准确性。
②适用场景:处理大规模数据、处理不平衡数据、处理高维数据。
③举例:根据免疫相关基因(IRG)表达谱数据和临床数据构建预后模型,对肺腺癌患者的预后进行预测。
④R语言代码:需要使用特定包实现(lightgbm包)
十七、神经网络回归(Quantile RegressiorNeural Network)
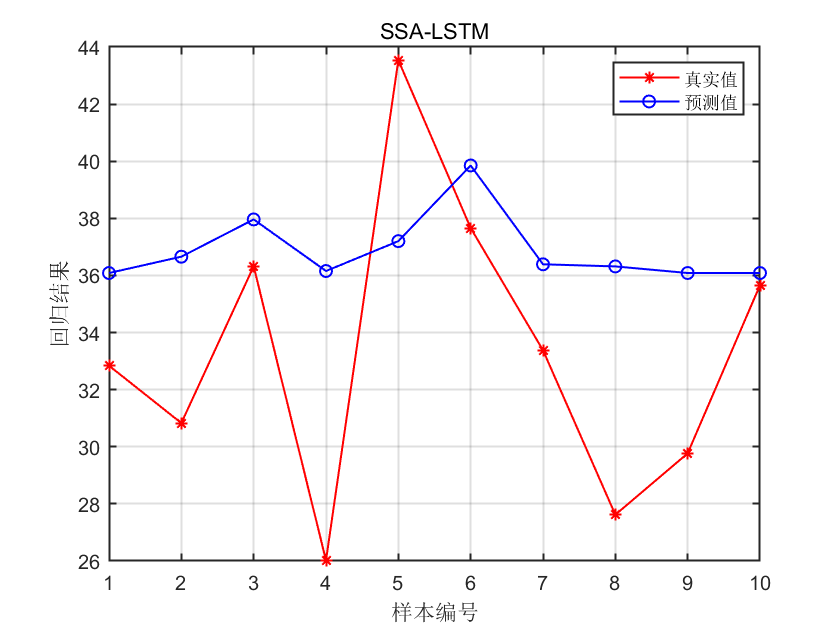
①定义:使用多层神经元网络进行回归预测,通过反向传播算法优化模型参办:
②适用场景:处理非线性关系、处理复杂数据模式、处理图像和文本数据。
③举例:用于预测小分子药物的活性,毒性和药代动力学特性。
④R语言代码:需要使用特定包实现(keras或caret包)
十八、K最近邻回归(K-Nearest Neighbors Regression)
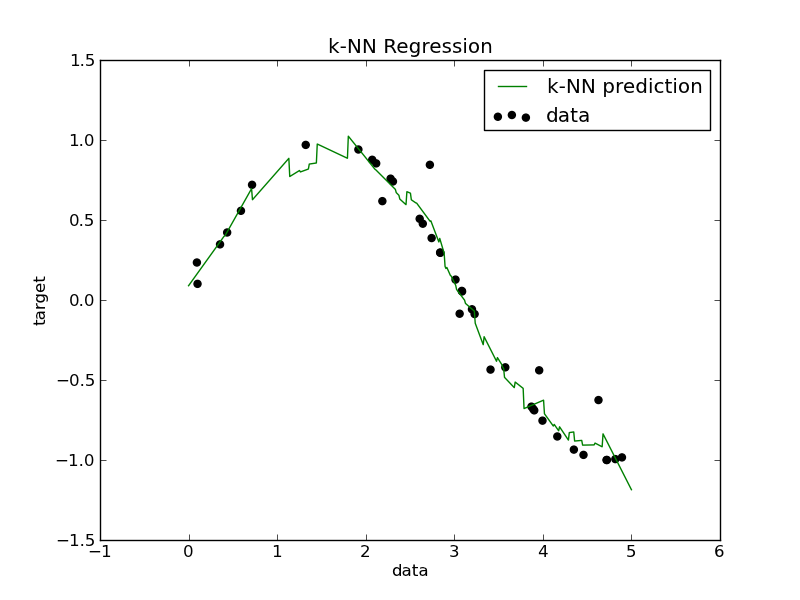
①定义:基于样本之间的相似性(如欧氏距离)进行回归预测,预测值为最近邻样本的响应变量的平均值或加权平均值。
②适用场景:当数据的局部结构对预测结果很重要时,例如空间数据或时间序列数据。
③举例:根据图像中细胞核的特性,包括半径、纹理等数据,判断肿瘤是否为良性。
④R语言代码:predictions <- knn(train = data,test = data,cl = labels, k = k)
文章出自:实验外包 想了解更多请关注:http://www.dj-cro.com/
本文标签: